
Spatio-temporal grounding describes the task of localizing events in space and time, e.g., in video data, based on verbal descriptions only. Models for this task are usually trained with human-annotated sentences and bounding box supervision. This work addresses this task from a multimodal supervision perspective, proposing a framework for spatio-temporal action grounding trained on loose video and subtitle supervision only, without human annotation.
To this end, we combine local representation learning, which focuses on leveraging fine-grained spatial information, with a global representation encoding that captures higher-level representations and incorporates both in a joint approach.
To evaluate this challenging task in a real-life setting, a new benchmark dataset is proposed, providing dense spatio-temporal grounding annotations in long, untrimmed, multi-action instructional videos for over 5K events. We evaluate the proposed approach and other methods on the proposed and standard downstream tasks, showing that our method improves over current baselines in various settings, including spatial, temporal, and untrimmed multi-action spatio-temporal grounding.
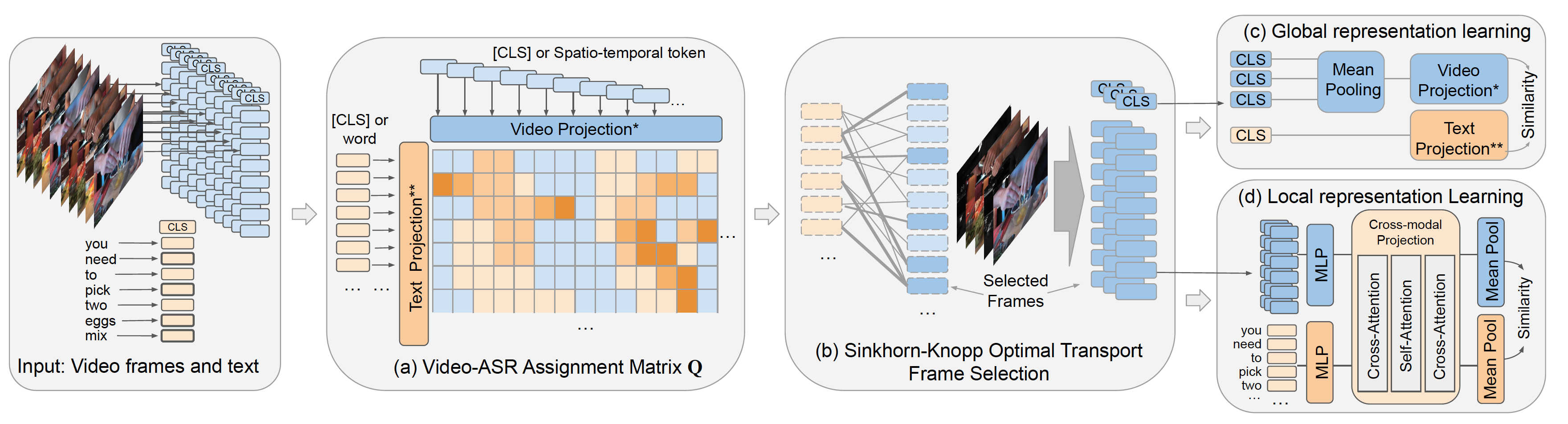
Spatio-temporal grounding approach. (a) We aim to select frames with groundable objects and actions. To this end, projected text features are matched with respective frame features. (b) Sinkhorn optimal transport is then leveraged to optimize the selected frames wrt. the text input. (c) Based on the selected frames, a global representation is learned to allow for temporal localization, as well as (d) A local representation to ground the action description in the spatial region.
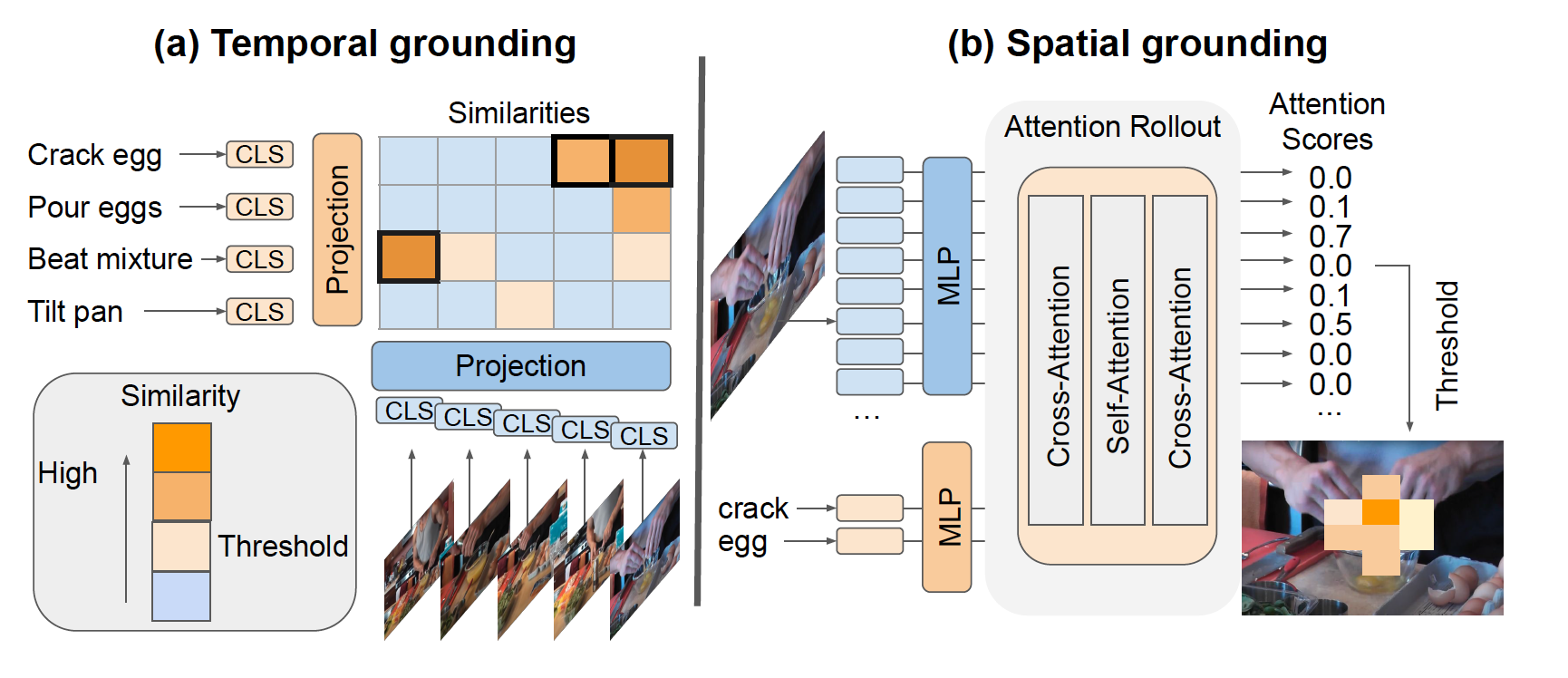
Spatio-temporal inference. Both representations are used for spatio-temporal grounding: Starting by predicting the action boundary, spatial grounding is performed on the selected frames using the predicted label to find corresponding regions.
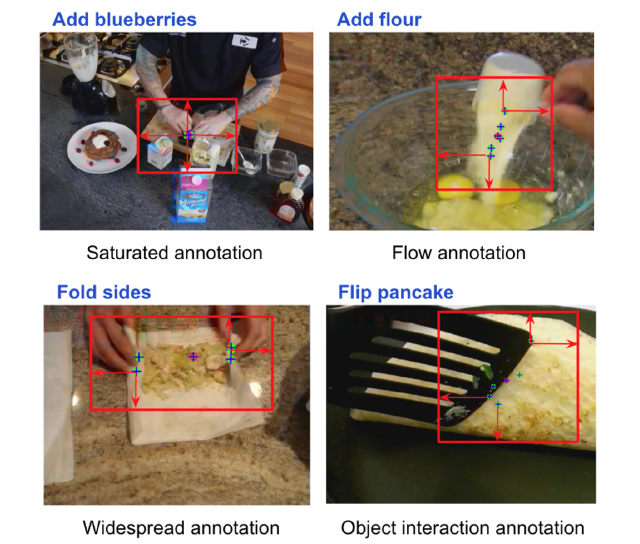
Visualization of the point annotation and automatic bounding box generation from points. The red point represents the mean of the five annotation points. The points annotation captures diverse patterns in various action types.

Red box: annotation. Heatmap: prediction. Baseline GLIP focuses on objects such as power, mixer, and pancake. Our method focuses on actions such as whisk and serve.
@inproceedings{chen2023and,
title={What, when, and where?--Self-Supervised Spatio-Temporal Grounding in Untrimmed Multi-Action Videos from Narrated Instructions},
author={Chen, Brian and Shvetsova, Nina and Rouditchenko, Andrew and Kondermann, Daniel and Thomas, Samuel and Chang, Shih-Fu and Feris, Rogerio and Glass, James and Kuehne, Hilde},
booktitle={Proceedings of the ieee/cvf conference on computer vision and pattern recognition},
year={2024}
}